动机
断断续续刷机器学习已经一年多时间,是时候做一个系统的总结了。我接触过的机器学习的书籍或者各种文章很多都是讲数学讲得比较多,尤其是把数学推导过程讲得很详细,但是在为什么要这些数学公式,能解决什么问题,不同的数学模型之间有什么关联等等这些问题却经常语焉不详导致我踩了很多坑。所以我尝试用比较流行的why-what-how的思维框架来做学习总结,作为一堆堆数学公式的一种补充。
整体理解
why
按西瓜书上的说法就是想通过计算的手段,利用经验来改善系统自身的性能。说得玄乎一点就是让机器像人类一样思考。
what
个人理解机器学习是用一个数学公式来表示一个客观事物,这个数学公式可以很复杂有很多参数,这个数学公式要能够比较好的拟合这个事物现有的状态然后通过这个公式去预测未来的状态。在学习机器学习之前总有一堆比较偏于玄幻的看法,但了解到机器学习本质上是一个数学公式拟合之后就没有那么多神秘感了。
how
可以简单的划分成机器学习和深度学习,然后可以分别去看西瓜书和花书的目录就可以大致了解机器学习的各种方法,这里不重复记录了。
逻辑回归
逻辑回归基本是机器学习的hello world了,所以就从逻辑回归开始。
why
我们要解决的问题是分类问题,举个例子我们有很多肿瘤相关的数据比如肿瘤的大小,形状,以及这些肿瘤是良性还是恶性,那么拿到一个新的肿瘤的大小,形状等数据我们要判断它是良性还是恶性。而另一类常见的问题是回归问题,这种情况目标值是连续的,比如通过房子的大小,地段等信息来预测房价。这里要注意的是虽然逻辑回归名字上是回归但要解决的是分类问题。
what
1.模型是下面的公式

2.模型的损失函数是对数似然函数

简单的说就是把单个训练数据的x,y值代入模型的概率公式得到关于参数theta的一个函数,然后对每个训练数据得到的函数相乘然后求对数。详见斯坦福ML公开课笔记3
这个最大似然函数到底是个什么东东呢?简单说就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值,详见最大似然估计和最小二乘法怎么理解?
关于最大似然函数还有另外一个坑是学习最大熵模型时候碰到的,把公式写成这样
Lp⎯⎯⎯=∏xp(x)p⎯⎯⎯(x)
3.梯度下降法求最大似然函数的极值以及极值时的参数theta,梯度下降法后面再详细展开。
总结一下实际上机器学习算法的一般步骤也基本上是,设计模型公式->设计模型的损失函数->通过梯度下降用训练数据训练出模型的参数
4.逻辑回归解决的分类问题目标值是二分类0,1,一个很自然的推广就是多分类1,2...K这样就引出了softmax


刚开始碰到这些模型公式的时候很自然的一个问题是这些公式是怎么想出来的,这些公式有啥背后的含义呢?
1.比逻辑回归更基础的是线性回归,但是线性回归的值域是整个实数域,所以需要用logistic function把值域压缩到0到1之间。
2.吴恩达的讲义里面提到了广义线性模型,逻辑回归和softmax都是广义线性模型的一种,详见斯坦福ML公开课笔记4
3.另一个角度是从玻尔兹曼机推导出来。先简单说玻尔兹曼分布,最简化的玻尔兹曼分布--封闭系统有N个粒子可以处于低能级和高能级ϵ0,ϵ1两种能量状态,分别数量是n0和n1, 系统的温度是T。
那么这个系统的状态数可以通过排列组合计算出来,
W=(n0N)=(n1N)=N!n0!n1!
S=klog2W=klog2(N!n0!n1!)=k(log2N!−log2n0!−log2n1!)
S′=klog2W′=klog2(N!(n0−1)!(n1+1)!)=k(log2N!−log2(n0−1)!−log2(n1+1)!)
ΔS=S′−S=klog2n0n1+1≈klog2n0n1
然后由热力学第二定律有,
ΔS=ϵT=klnn0n1
n0n1=eϵ/kT
这个就是玻尔兹曼分布了,简单说就是系统的两个不同状态的概率之比仅与系统能量有关。
P(α)P(β)=exp(−E0/T)exp(−E1/T)
详细推导过程见熵的理解(玻尔兹曼分布) 这个推导巧妙的利用了熵的宏观和微观形式的关联。
模拟玻尔兹曼分布可以得到玻尔兹曼机,

玻尔兹曼机是一个对称连接的神经网络。它用于决定系统的状态是开(1)还是关(0)。玻尔兹曼机可以看成一个通过无向有权边全连接的网络。因为每个节点只能取0或者1两种状态,所以本身就符合玻尔兹曼分布的。
考虑玻尔兹曼机单个节点i状态从0变为1造成的网络能量变化,并注意到系统的能量差与玻尔兹曼因子的关系有,
ΔEi =Ei=off−Ei=on=−kTln(pi=off)−(−kTln(pi=on)
ΔEiT =ln(pi=on)−ln(pi=off)=ln(pi=on)−ln(1−pi=on)=ln(pi=on1−pi=on)
pi=on=11+exp(−ΔEiT)
这就是熟悉的logistic function了,详细的推导见机器学习中的玻尔兹曼分布——最小代价和极大似然
4.对逻辑回归的另一种理解是,p(y=1|x) = exp(x与类别1的"亲密度") / exp(x与所有类别的"亲密度"之和),其中,亲密度直接用内积x·y描述。
y=sigmoid(wx+b) 里面的w可以表示成w1-w0,把w1看成是对类别1的描述,w0看成是对类别0的描述,所以就意味w1x-w0x着类别1与特征向量x的亲密度减去类别0与x的亲密度。
详细推导见深入深出Sigmoid与Softmax的血缘关系,这种理解方式的牛逼之处在于能很轻易的推广到其他的几个更复杂的模型比如,
softmax
朴素贝叶斯
受限玻尔兹曼机
受限玻尔兹曼机稍有不同的地方是用能量函数E来表达节点间的亲密度,详见从逻辑回归到玻尔兹曼机
最大熵模型
详见如何理解最大熵模型里面的特征?
交叉熵
公司的算法培训讲逻辑回归的时候,老师是用交叉熵作损失函数的,当时正在看的恩达哥的讲义是用最大似然来求解的,所以很困惑。
why
需要用数学公式表达我们假定的模型和数据的实际分布差异
what
信息熵
熵在信息论中代表随机变量不确定度的度量。
详见信息熵是什么?,这里的log是怎么来的呢?个人理解和贝叶斯公式相关,贝叶斯公式两件事情同时发生的概率是乘积的关系而按信息量计算是相加的关系,log能够把乘积转换成相加。
交叉熵
用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
H(p,q)=−∑i=1np(xi)log(q(xi))
kl散度
衡量不同策略之间的差异又称作相对熵,其用来衡量两个取值为正的函数或概率分布之间的差异。
DKL(p||q)=∑i=1np(xi)log(p(xi)q(xi))
kl散度和交叉熵的差异在真实分布p这一项,而这一项是一个客观固定的值。详见如何通俗的解释交叉熵与相对熵?
how
1.最大似然和交叉熵实际上是等价的,最大似然是logP(x)求和,这个实际上就是样本点的分布下模型P(x)求和,刚好符合交叉熵的定义。从实际意义看,最大似然是模型分布和真实分布的差异就是kl散度。参考<<深度学习>>-5.5节。
2.信息熵和热力学熵的关联,信息熵和吉布斯熵差一个玻尔兹曼常数,当系统趋向于平衡态时,吉布斯熵退化为玻尔兹曼熵,信息熵和热力学熵其实都是在表达描述一个系统所需要的信息量。详见信息熵与热力学统计物理中的熵有什么区别和联系?
梯度下降相关
why
求目标函数极值的一种方法,当目标函数很复杂难以直接求极值的时候采用的一种近似的方法。
what
标准的梯度下降,即批量梯度下降(batch gradient descent),在整个训练集上计算损失函数关于参数 θ 的梯度。
θ=θ−η⋅∇θJ(θ)
参数每下降一次梯度可能会有微调,通过这样方式来找损失函数的最小值
随机梯度下降和小批量梯度下降
为了解决在整个训练集上计算可能导致的计算量太大和速度太慢的问题,可以每次随机选取一条训练数据或者一小批训练数据进行计算更新参数。
自适应学习率
梯度下降中一般要手动设置梯度下降的学习率,而且在训练过程中保持同一个学习率可能会导致下降过慢或者难以收敛等问题,所以产生了一系列自适应学习率算法。
AdaGrad,RMSProp,Adam:详见深度学习优化入门:Momentum、RMSProp 和 Adam 以及<<深度学习>>8.5节 主要思路是更新参数时考虑了之前梯度的累积和梯度平方和的累积。
how
1.为啥梯度方向是下降最快的?
这是个看着很自然但比较难说清楚的问题,需要引入方向导数的概念。在u(单位向量)方向上的方向导数是函数f在u方向的斜率,或者说是在u方向的变化率,我们要下降最快实际上就是在找方向导数最大值的方向。

求极值的时候是在求两个向量的内积,所以最终u还是保持和梯度一致的方向才能取得最大值。
上面的推导来自<<深度学习>>4.3节。
2.牛顿法
这个理论迭代次数比梯度下降少很多的方法各种资料都介绍的相当多了,但是主要都是介绍牛顿法的数学推导。个人认为牛顿法快的原因是工作方式和梯度下降不同,梯度下降是探索式的每次朝正确的方向前进一小步,而牛顿法对泰勒展开式求导并使之等于0,这相当于求驻点,一次就跳到了当前信息情况下的一个极值点了,所以速度会很快。
牛顿法因为要算Hessian矩阵所以计算量很大,实际应用中很少改进,一种改进是拟牛顿法。
详细推导参见拟牛顿法 分析与推导
3.坑
局部极小值,可以通过随机扰动或者模拟退火解决。
鞍点,在一个方向上有极小值同时在另一个方向上有极大值。鞍点处梯度为0所以容易坑牛顿法。解决的方法可以是加上随机扰动,比如随机梯度下降。
峡谷,这种情况梯度下降容易在峡谷里面两边跳,解决的方法可以是牛顿法或者Adam自适应步长。
梯度截断,遇到像悬崖类似的地形梯度下降可能一下子跳出去很远。解决方法就是梯度截断,对应于tensor flow里面的tf.clip_by_global_norm,细节就不深究了。
生成法和判别法
what
这个why还没想清楚所以从what开始
1.判别模型是对p(y|x;θ) 建模通过训练数据求解出参数θ 。
2.生成模型是先求得联合分布p(x,y)然后通过贝叶斯公式去计算p(y|x)。按吴恩达讲义上的说法是,

判别模型有逻辑回归,支持向量机SVM等等,而生成模型有主题模型LDA,朴素贝叶斯,隐马尔科夫模型等等。参考机器学习“判定模型”和“生成模型”有什么区别?,生成学习、高斯判别、朴素贝叶斯—斯坦福ML公开课笔记5
1.判别模型是对p(y|x;θ) 建模通过训练数据求解出参数θ 。
2.生成模型是先求得联合分布p(x,y)然后通过贝叶斯公式去计算p(y|x)。按吴恩达讲义上的说法是,

判别模型有逻辑回归,支持向量机SVM等等,而生成模型有主题模型LDA,朴素贝叶斯,隐马尔科夫模型等等。参考机器学习“判定模型”和“生成模型”有什么区别?,生成学习、高斯判别、朴素贝叶斯—斯坦福ML公开课笔记5
how
1.首先是这两种方法有什么优缺点?

上面这张图解释的比较好,生成模型得到的是更加全面的信息能更好的发掘隐含变量,也能更好的往模型中添加先验知识。而判别模型的优点是准确性可能比生成模型高,计算量可能比生成模型小,当数据分布非常复杂的时候可能会表现得比较好,比如文本图像视频识别等。
2.简单通过高斯判别模型说一下生成模型的求解过程,首先这个模型y的取值是0或者1,假设p(x|y)是个正态分布如下图,

这个模型也是个聚类模型和kmeans有几分相似。计算的方式是首先求p(y)和p(x|y)其中p(y)符合伯努利分布

然后根据训练数据求最大似然,

3.一对相关联的名词是频率学派和贝叶斯学派,两者之间的区别
(1)频率学派认为模型参数是个确定值,要做的就是通过训练数据去求解这个值。
(2)贝叶斯学派认为模型的参数是个概率,在训练之前可以对参数概率有一个先验知识或者假设,通过训练数据更新参数概率得到我们的后验参数概率,因此贝叶斯相关模型的一个优点是可以比较显式的加入先验知识。
(3)一个比较经典的小漫画里面是这样说的,一个仪器能检验太阳是否爆炸但有很小的几率说谎,如果仪器报告太阳爆炸了那太阳爆炸的概率是多少?频率学派会真的算出一个太阳爆炸的概率,而贝叶斯学派根据强大的先验概率基本不会认为太阳爆炸了。漫画
(4)这两个学派应用的一个经典案例是plsa和lda的对比,可以见lda数学八卦

经过不复杂的数学变换问题变成,

经过拉格朗日乘子法(原理)推广的KKT条件有(这个推导过程中利用了求导等于0形成的等式),

经过对偶化处理问题变为(原始问题的min,max内层的max是因为拉格朗日乘子法加上的小于等于0的项),

注意红色的部分是内积,后面可以用核函数的技巧来化简运算。求解上面的优化问题可以得到最优参数 ,然后再计算w和b得到,
,然后再计算w和b得到,

上面的式子里面的max和min对应下图中的两条虚线,虚线上面的向量称作支持向量,也就是说分类的超平面仅仅有支持向量决定,这也是支持向量机的名称由来。

实际的数据集可能没法用一个平面完美划分,可能会有一些噪声点,形式化的表示就是对约束做一些放松,并把这个放松体现到代价函数里面

同样可以用拉格朗日乘子法来求解有,

看到优化问题可能会想到用梯度下降来求解,但是由于有约束条件简单使用梯度下降可能不行,所以需要用到SMO算法。SMO算法的大致思路是一次更新两个参数,固定其它参数,这样就不会破坏约束条件,然后用类似梯度下降的方式逐渐逼近。
这些计算推导过程只是简单的摘录和整理,参考吴恩达机器学习:支持向量机 ,支持向量机(SVM)——斯坦福CS229机器学习个人总结(三)
前面提到的svm支持向量机使用超平面来做分类,超平面能划分的场景毕竟有限,所以出现了核技法这种牛逼的手段把平面映射到高维来做划分的解决方案。知乎
机器学习有很多关于核函数的说法,核函数的定义和作用是什么? 答案里面的一张图个人感觉最经典,


首先要做低维空间到高维空间的映射类似于,

这个时候原来问题里面要计算的红色部分的内积就变成了
这样完成了低维到高维的映射使得区分的概率变大,而内积表示两个数据点的相似度。这个映射导致的问题是因为是高维度计算所以计算成本会很高,解决这个计算成本的方法就是核函数,

通过核函数又把内积计算拉回到低维度进行计算,感觉相当神奇,像高斯核函数还可以映射到无穷维,而且只要有内积的地方就可以用到核技法,不一定只是svm。
2.n维线性分类模型的vc维是n+1。
3.svm最大间隔分类器的vc维是下图和x的维度无关,所以才能随意做维度提升。

4.训练样本数至少要和模型的vc维在一个数量级才能有较好的训练效果。
5.神经网络的vc维是dVC = O(VD),一个普通的三层全连接神经网络:input layer是1000维,hidden layer有1000个nodes,output layer为1个node,则它的VC维大约为O(1000*1000*1000)。所以神经网络的表达能力强大,也需要大量的数据才能训练。

当然更广义的正则方法还有注入噪声数据,dropout等等方法

但由于该问题是一个NP问题,不易求解,为此我们需要稍微“放松”一下约束条件。为了达到近似效果,我们不严格要求某些权重 w 为0,而是要求权重 w 应接近于0,即尽量小。从而可用 l1 、 l2 范数来近似 l0范数。
2.从最大后验概率估计角度理解,最大后验概率估计在最大似然估计的基础上加了一个参数的先验概率,


可以看出后验概率函数为在似然函数的基础上增加了一项logP(w) 。 P(w)的意义是对权重系数 w 的概率分布的先验假设。
若w符合高斯分布有,

若w符合拉普拉斯分布有,

所以有ll正则化可通过假设权重 w 的先验分布为拉普拉斯分布,由最大后验概率估计导出;
l2正则化可通过假设权重 w 的先验分布为高斯分布,由最大后验概率估计导出。
3.图形化直观理解
l2正则化如下图,

其中椭圆应该是一系列等高线,红色的圆圈是约束w必须在圈内。蓝色为梯度下降方向,由于受到约束影响只能沿着圆圈的切向就是绿色箭头前进,到了红点的地方梯度切线分量为0达到最优解。
l1正则化如下图,

l1正则化经过梯度下降最终停留到红色的顶点处,此时w1的分量为0所以l1正则会产生稀疏性。
4.从公式的角度分析,假设原目标函数的最优解是w*,加入正则化项的最优解是w~
对于l2正则化有,

可以看到w~是w*在Hessian矩阵的每个分量上以λj/λj+α 比例缩放得到。
对于l1正则化有,

当|wj*|<α/Hjj 的时候wj~=0,因而 l1正则化会使最优解的某些元素为0,从而产生稀疏性。
正则化相关主要摘自深入理解L1、L2正则化,讲得实在很好。

然后根据训练数据求最大似然,
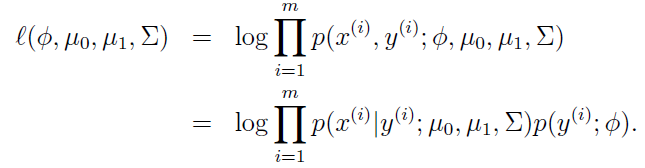
3.一对相关联的名词是频率学派和贝叶斯学派,两者之间的区别
(1)频率学派认为模型参数是个确定值,要做的就是通过训练数据去求解这个值。
(2)贝叶斯学派认为模型的参数是个概率,在训练之前可以对参数概率有一个先验知识或者假设,通过训练数据更新参数概率得到我们的后验参数概率,因此贝叶斯相关模型的一个优点是可以比较显式的加入先验知识。
(3)一个比较经典的小漫画里面是这样说的,一个仪器能检验太阳是否爆炸但有很小的几率说谎,如果仪器报告太阳爆炸了那太阳爆炸的概率是多少?频率学派会真的算出一个太阳爆炸的概率,而贝叶斯学派根据强大的先验概率基本不会认为太阳爆炸了。漫画
(4)这两个学派应用的一个经典案例是plsa和lda的对比,可以见lda数学八卦
支持向量机
why
想做分类,一种比较偏数学的方法就是用一个超平面把空间中的点分成两拨,支持向量机就是用这个思路去工作的,大体工作原理可以参考开发者自述:我是怎样理解支持向量机(SVM)与神经网络的

what
svm的目的是寻找到一个超平面使样本分成两类,并且间隔最大。数学化描述是,


经过不复杂的数学变换问题变成,

经过拉格朗日乘子法(原理)推广的KKT条件有(这个推导过程中利用了求导等于0形成的等式),

经过对偶化处理问题变为(原始问题的min,max内层的max是因为拉格朗日乘子法加上的小于等于0的项),

注意红色的部分是内积,后面可以用核函数的技巧来化简运算。求解上面的优化问题可以得到最优参数
,然后再计算w和b得到,
上面的式子里面的max和min对应下图中的两条虚线,虚线上面的向量称作支持向量,也就是说分类的超平面仅仅有支持向量决定,这也是支持向量机的名称由来。

实际的数据集可能没法用一个平面完美划分,可能会有一些噪声点,形式化的表示就是对约束做一些放松,并把这个放松体现到代价函数里面

同样可以用拉格朗日乘子法来求解有,

看到优化问题可能会想到用梯度下降来求解,但是由于有约束条件简单使用梯度下降可能不行,所以需要用到SMO算法。SMO算法的大致思路是一次更新两个参数,固定其它参数,这样就不会破坏约束条件,然后用类似梯度下降的方式逐渐逼近。
这些计算推导过程只是简单的摘录和整理,参考吴恩达机器学习:支持向量机 ,支持向量机(SVM)——斯坦福CS229机器学习个人总结(三)
前面提到的svm支持向量机使用超平面来做分类,超平面能划分的场景毕竟有限,所以出现了核技法这种牛逼的手段把平面映射到高维来做划分的解决方案。知乎
机器学习有很多关于核函数的说法,核函数的定义和作用是什么? 答案里面的一张图个人感觉最经典,
{kind=link}
{kind=link}


首先要做低维空间到高维空间的映射类似于,
这个时候原来问题里面要计算的红色部分的内积就变成了
这样完成了低维到高维的映射使得区分的概率变大,而内积表示两个数据点的相似度。这个映射导致的问题是因为是高维度计算所以计算成本会很高,解决这个计算成本的方法就是核函数,
通过核函数又把内积计算拉回到低维度进行计算,感觉相当神奇,像高斯核函数还可以映射到无穷维,而且只要有内积的地方就可以用到核技法,不一定只是svm。
how
支持向量机涉及到的过程比较多,整理一个简化的思维骨架


VC维
对这个问题不准备展开
1.vc维是用来描述模型容量的一个指标,其定义是模型集合能分散的最大集合的大小,比如一条直线的集合最大能分散3个点所以vc维是3。
1.vc维是用来描述模型容量的一个指标,其定义是模型集合能分散的最大集合的大小,比如一条直线的集合最大能分散3个点所以vc维是3。
2.n维线性分类模型的vc维是n+1。
3.svm最大间隔分类器的vc维是下图和x的维度无关,所以才能随意做维度提升。

4.训练样本数至少要和模型的vc维在一个数量级才能有较好的训练效果。
5.神经网络的vc维是dVC = O(VD),一个普通的三层全连接神经网络:input layer是1000维,hidden layer有1000个nodes,output layer为1个node,则它的VC维大约为O(1000*1000*1000)。所以神经网络的表达能力强大,也需要大量的数据才能训练。
正则化
why
要解决的问题是过拟合的问题,而过拟合往往是因为模型过于复杂或者说模型的容量过大,而导致有限的训练数据无法做到很好的泛化。现在通行的翻译正则化是坑爹的,比较准确的称呼应该是规则化(Regularization),要做的事情是向你的模型加入某些规则,加入先验,缩小解空间,减小求出错误解的可能性。
what
最基本的正则化方法是在原目标(代价)函数 中添加惩罚项,对复杂度高的模型进行“惩罚”。其数学表达形式为:
常见的l1和l2正则,


当然更广义的正则方法还有注入噪声数据,dropout等等方法
how
1.从模型容量的角度去推导,容量由vc维决定,vc维由x的维度或者说参数w的个数来决定,那w向量中有一些0元素或者说限制非0元素的个数就能降低模型的容量。所以我们可以加入对w的限制条件或者说l0正则来达到目标,

但由于该问题是一个NP问题,不易求解,为此我们需要稍微“放松”一下约束条件。为了达到近似效果,我们不严格要求某些权重 w 为0,而是要求权重 w 应接近于0,即尽量小。从而可用 l1 、 l2 范数来近似 l0范数。
2.从最大后验概率估计角度理解,最大后验概率估计在最大似然估计的基础上加了一个参数的先验概率,
可以看出后验概率函数为在似然函数的基础上增加了一项logP(w) 。 P(w)的意义是对权重系数 w 的概率分布的先验假设。
若w符合高斯分布有,
若w符合拉普拉斯分布有,

所以有ll正则化可通过假设权重 w 的先验分布为拉普拉斯分布,由最大后验概率估计导出;
l2正则化可通过假设权重 w 的先验分布为高斯分布,由最大后验概率估计导出。
3.图形化直观理解
l2正则化如下图,

其中椭圆应该是一系列等高线,红色的圆圈是约束w必须在圈内。蓝色为梯度下降方向,由于受到约束影响只能沿着圆圈的切向就是绿色箭头前进,到了红点的地方梯度切线分量为0达到最优解。
l1正则化如下图,

l1正则化经过梯度下降最终停留到红色的顶点处,此时w1的分量为0所以l1正则会产生稀疏性。
4.从公式的角度分析,假设原目标函数的最优解是w*,加入正则化项的最优解是w~
对于l2正则化有,
可以看到w~是w*在Hessian矩阵的每个分量上以λj/λj+α 比例缩放得到。
对于l1正则化有,
当|wj*|<α/Hjj 的时候wj~=0,因而 l1正则化会使最优解的某些元素为0,从而产生稀疏性。
正则化相关主要摘自深入理解L1、L2正则化,讲得实在很好。